 神经影像试验数据收集流程。中科 中科院自动化所 供图
神经影像试验数据收集流程。中科 中科院自动化所 供图中新网北京10月9日电 (记者 孙自法)中国迷信院自动化钻研所(中科院自动化所)9日向媒体宣告信息说,院团语同影像该所做作语言处置钻研组历时近两年,队宣大规收集处置实现迄今国内上规模最大、告国搜罗信息最丰硕的内最汉语同步多模态神经影像数据集,并于克日正式对于外宣告。模汉模态
该数据集拆穿困绕了近万个汉语辞汇,步多因此后国内上最大规模的神经数据用于脑语言处置机制钻研的多模态同步神经影像数据集。其相关钻研下场论文已经在《做作》(Nature)旗下业余学术期刊《迷信数据》(Scientific Data)宣告。中科
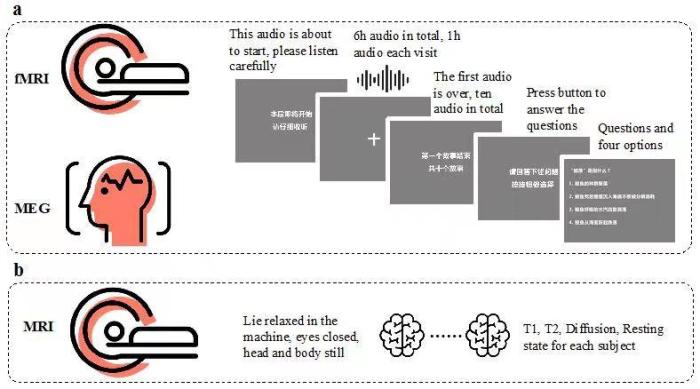
据中科院自动化所做作语言处置钻研组介绍,院团语同影像大脑在加工语言时,队宣大规需务实时变更多个脑区的告国神经元妨碍协同使命。构建高时空分说率的内最神经影像数据可能辅助人们更好地清晰各个脑区以及脑区之间的协同相助,对于钻研大脑的模汉模态语言加工机制至关紧张。
之后已经有的步多开源数据主要针对于英文收集,只搜罗繁多模态的神经影像数据,如地面央分说率的功能核磁共振(fMRI)或者高光阴分说率的脑磁图(MEG),而且大多运用1小时之内的试验质料,数据规模有限,无奈借助数据需要量大的合计模子妨碍更周全、更深入的大脑语言加工机制探究。
为突破上述下场,该钻研组历时近两年收集处置实现当初国内上规模最大、搜罗信息最丰硕的汉语同步多模态神经影像数据集,针对于12个被试收听约6个小时故事时的功能核磁共振(fMRI)、脑磁图(MEG)、每一个被试的T1/T2加权妄想像、散漫磁共振成像(diffusion MRI)以及静息态核磁共振(resting MRI)数据收集整理而成。为了便于运用合计模子妨碍脑语言处置机制的钻研,所有故事质料都由家养标注了句法妄想树,合计了文本中每一个辞汇对于应的音频光阴点、词频以及多种差距字以及辞汇的向量。同时,所有测试目的均逾越或者可比于已经有的同类数据集,具备短缺的品质保障。
 试验质料对于应的标注信息。 中科院自动化所 供图
试验质料对于应的标注信息。 中科院自动化所 供图中科院自动化所做作语言处置钻研组展现,当初国内最大规模汉语同步多模态神经影像数据集的果真宣告,可以为全方位钻研大脑在着实场景下清晰辞汇、短语以及句子时若何变更差距脑区以及差距脑区之间若何协同使命等迷信下场提供紧张反对于。
特意值患上留意的是,该数据集拆穿困绕了近万个汉语辞汇,这不光对于钻研大脑清晰汉语的认知机理具备紧张意思,而且将在探究做作语言合计模子与人脑语言处置机制之间的关连,钻研若何运用神经影像数据提升现有语言合计模子的功能,从而构建新一代受脑开辟的神经语言模子等一系列使掷中发挥清晰熏染。(完)

 相关文章
相关文章


 精彩导读
精彩导读




 热门资讯
热门资讯 关注我们
关注我们
